Para altas taxas de compressão use .zst
Realize compressões mais rápidas e tão compactas ou mais compactas que o formato .xz
Com o zstd você compacta mais rápido, com mais qualidade e menor uso do processador. Use o seguinte comando para compactar:
zstd arquivo -o arquivo.zst
O padrão é o nível 3 de compressão. Para uma maior compressão use o nível entre 1 a 19:
zstd arquivo -19 -o arquivo.zst
Para realizar uma compressão ainda mais elevada (o máximo é o nível 22) use, a opção ultra, para desbloquear o nível pretendido:
zstd arquivo --ultra -22 -o arquivo.zst
Para comprimir diretórios, usando .tar, com a compressão padrão (nível 3), execute o seguinte comando:
tar --zstd -cf diretório.tar.zst diretório
Para compressão máxima (nível 22) em diretórios, é recomendado usar o empacotamento .tar (sem qualquer compressão, apenas empacotar) e logo após compactar, assim:
tar -cf diretório.tar diretório
Para fazer tudo de uma vez, faça assim:
tar -cf diretório.tar diretório; zstd diretório.tar --ultra -22 -o diretório.tar.zst
Para descomprimir é fácil você pode usar o tar para diretórios empacotados ou, unzstd para arquivos compatados:
tar -xf diretório.tar.zst ou unzstd arquivo.zst
Benchmarks
| Compressor | Ratio | Compressão | Descompressão |
|---|---|---|---|
| zstd 1.3.4 -1 | 2.877 | 470 MB/s | 1380 MB/s |
| zlib 1.2.11 -1 | 2.743 | 110 MB/s | 400 MB/s |
| brotli 1.0.2 -0 | 2.701 | 410 MB/s | 430 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 550 MB/s | 710 MB/s |
| lzo1x 2.09 -1 | 2.108 | 650 MB/s | 830 MB/s |
| lz4 1.8.1 | 2.101 | 750 MB/s | 3700 MB/s |
| snappy 1.1.4 | 2.091 | 530 MB/s | 1800 MB/s |
| lzf 3.6 -1 | 2.077 | 400 MB/s | 860 MB/s |
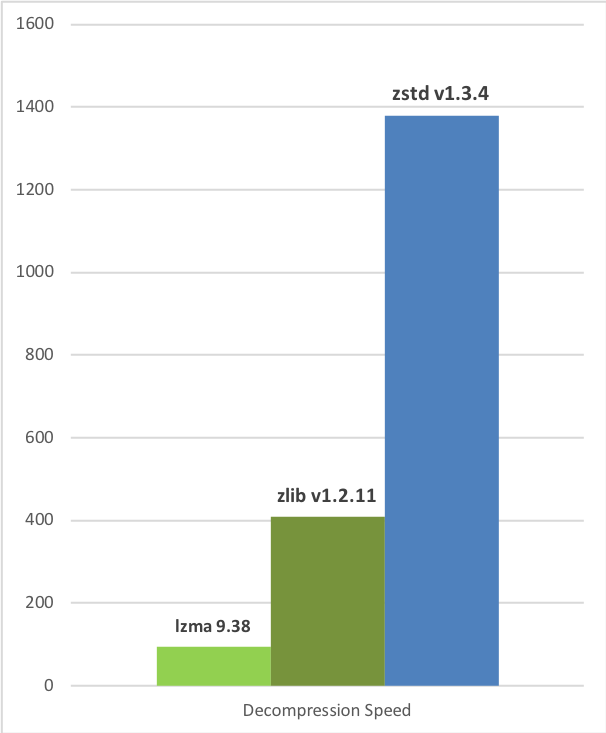
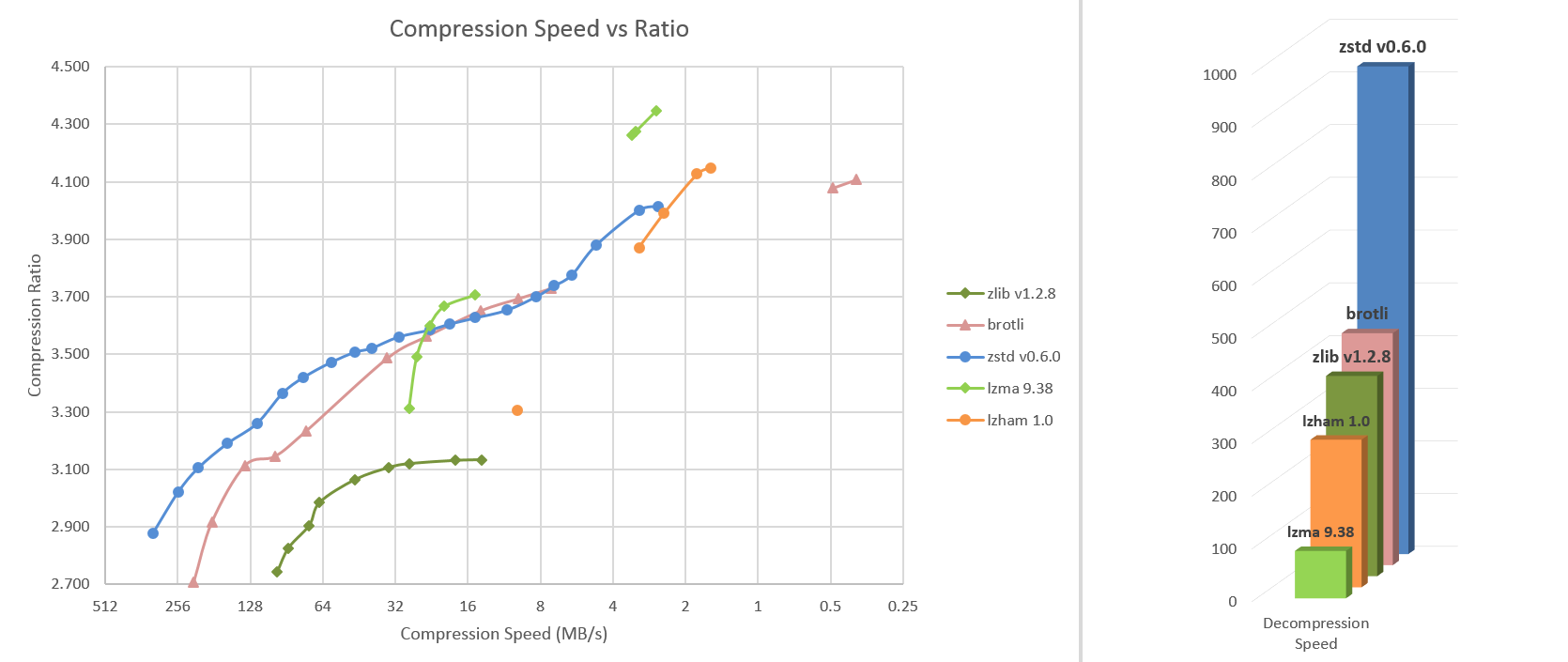
O Zstd pode trocar a velocidade de compactação por taxas de compactação mais fortes. É configurável por pequeno incremento. A velocidade de descompactação é preservada e permanece praticamente a mesma em todas as configurações, uma propriedade compartilhada pela maioria dos algoritmos de compactação LZ, como zlib ou lzma.
Os testes a seguir foram executados em um servidor executando o Linux Debian (Linux versão 4.14.0-3-amd64) com uma CPU Core i7-6700K a 4.0GHz, usando lzbench, um benchmark de memória de código aberto da @inikep compilado com o gcc 7.3.0, no corpo de compressão da Silesia.
| Velocidade de Compressão vs Fator | Velocidade de Descompressão |
|---|---|
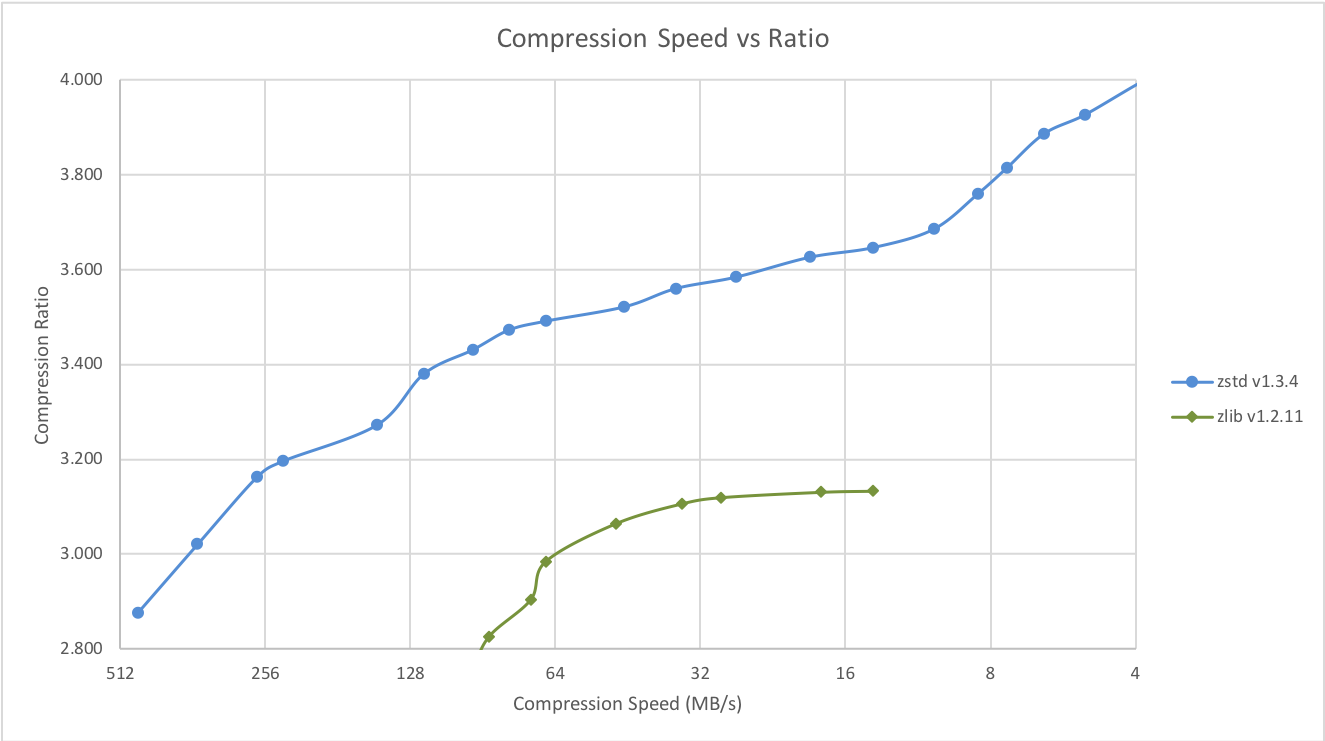 |  |
Vários algoritmos podem produzir uma taxa de compressão mais alta, mas em velocidade mais lenta, ficando fora do gráfico. Para uma imagem maior, incluindo modos muito lentos, clique neste link.
O caso da compactação de dados pequenos
Os gráficos anteriores fornecem resultados aplicáveis a cenários típicos de arquivo e fluxo (vários MB). Dados pequenos vêm com diferentes perspectivas.
Quanto menor a quantidade de dados a compactar, mais difícil é compactar. Esse problema é comum a todos os algoritmos de compactação e o motivo é que os algoritmos de compactação aprendem com dados anteriores como compactar dados futuros. Porém, no início de um novo conjunto de dados, não há “passado” a ser construído.
Para resolver essa situação, o Zstd oferece um modo de treinamento, que pode ser usado para ajustar o algoritmo para um tipo de dados selecionado. O treinamento do Zstandard é obtido fornecendo-lhe algumas amostras (um arquivo por amostra). O resultado desse treinamento é armazenado em um arquivo chamado “dicionário”, que deve ser carregado antes da compactação e descompactação. Usando este dicionário, a taxa de compactação alcançável em pequenos dados melhora drasticamente.
O exemplo a seguir usa o conjunto de amostras github-users, criado a partir da API pública do github. Consiste em aproximadamente 10K registros, pesando cerca de 1KB cada.
| Taxa de Compressão | Velocidade de Compressão | Velocidade de Descompressão |
|---|---|---|
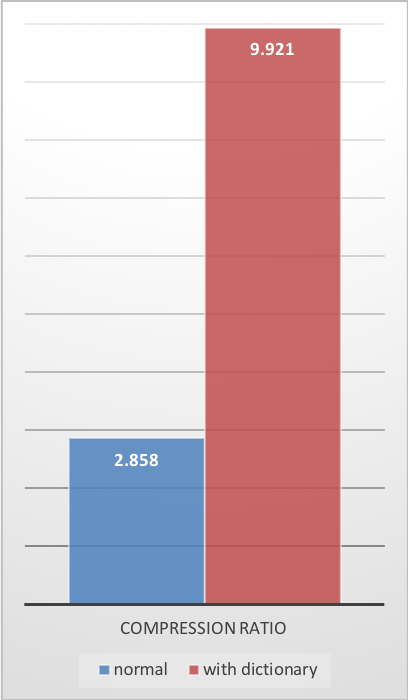 | 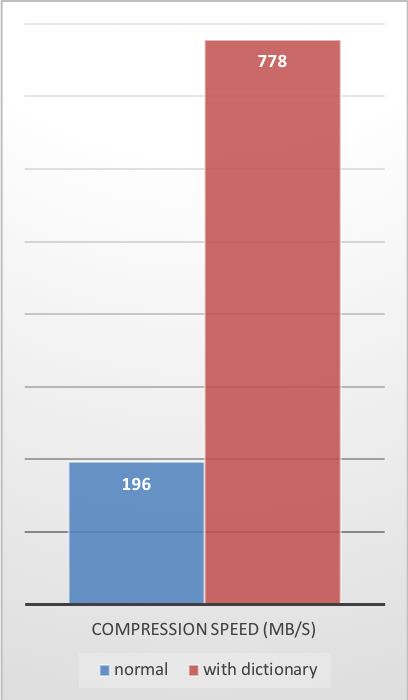 | 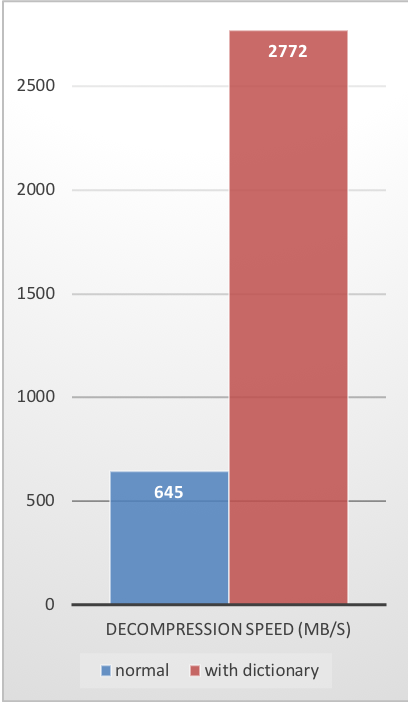 |
Esses ganhos de compactação são alcançados ao mesmo tempo em que fornecem velocidades mais rápidas de compactação e descompressão.
O treinamento funciona se houver alguma correlação em uma família de pequenas amostras de dados. Quanto mais específico for um dicionário de dados, mais eficiente ele será (não há dicionário universal). Portanto, a implantação de um dicionário por tipo de dados fornecerá os maiores benefícios. Os ganhos do dicionário são efetivos principalmente nos primeiros KB. Em seguida, o algoritmo de compactação usará gradualmente o conteúdo decodificado anteriormente para compactar melhor o restante do arquivo.

{kind=link}